Monitorización de contenedores Docker con cAdvisor, Prometheus y Grafana

Monitorización
Después de conseguir instalar Jam Session en mi Docker y ver como montan la monitorización del sistema me han entrado ganas de probar a montar algo para todos los contenedores instalados en mi VPS.
- Monitoring Docker Services with Prometheus
- Monitoring setup with docker-compose
- Un template básico en Github
- Otro docker-compose programado por Eisteinish Muy completo, también en Github
Prometheus y cAdvisor
Inspirándonos en la configuración de monitorización que venía con Jam Session, vamos a intentar configurar un sistema propio. Vamos a usar también Grafana y Prometheus, pero añadiendo cAdvisor a la receta como nos proponen en la propia web de Prometheus (la combinación de cAdvisor, Prometheus y Grafana parece un estándar de facto en la industria)
cAdvisor es un software de Google, escrito en Go, y programado específicamente para la captura de métricas de contenedores; necesita acceso a varios directorios del host (que mapearemos con bind-mounts en Docker) para capturar los datos. cAdvisor expone el puerto 8080 (interfaz web y REST api) y por defecto permite a Prometheus acceder a varias métricas.
Prometheus es un toolkit de monitorización de métricas. Prometheus almacena las métricas como series temporales, a las que se pueden asignar pares etiqueta valor opcionales (parece un funcionamiento análogo al de InfluxDB) Soporta un lenguaje de consultas denominado PromQL. Puede capturar métricas por pulling o por pushing. Normalmente, en procesos de vida larga, Prometheus hace scrapping en los orígenes de métricas definidos, pero también implementa un push-gateway para procesos de vida muy corta.
Prometheus, igual que cAdvisor, expone un interfaz web a través del cual podemos hacer consultas con PromQL y ver los resultados en modo tabla o modo gráfico.
Pero esto es solo la punta del iceberg. Entre otras cosas:
- Prometheus nos da la posibilidad de instalar otras dos aplicaciones: Alertmanager y Node Exporter
- Alertmanager se encarga de gestionar las Alertas que Prometheus genere a partir de las métricas para canalizarlas a distintos sistemas de comunicación (nos da muchísimas opciones)
- Node Explorer está especializado en monitorizar métricas de la máquina host.
- Hay todo un ecosistema de bibliotecas y clientes para exportar métricas compatibles con Prometheus desde multitud de sistemas.
cAdvisor
Empezamos por configurar el contenedor de cAdvisor. Creamos un directorio mon para nuestros nuevos contenedores de monitorización, y en ese directorio nuestro fichero docker-compose.yml:
|
|
La configuración no tiene mucho misterio, hacemos bind-mounts de todos los recursos del host que necesita cAdvisor para recolectar métricas. Como queremos consumir todas las métricas en local comentamos el mapeo de puertos por que no queremos que el VPS deje acceso desde internet a las métricas. Por la misma razón Traefik no necesita saber nada de este contenedor (ya que no será accesible desde fuera)
En principio entiendo que cAdvisor captura las métricas directamente desde Docker así que de momento lo conectamos solo a la red backend.
Con esto tenemos todo listo para lanzar el servicio cAdvisor con dcupd (mi alias para docker-compose up -d). Para comprobar el contenedor desde fuera del VPS podemos hacerlo por un túnel ssh:
|
|
Ahora podemos conectar nuestro navegador a http://localhost:9081 y comprobar que cAdvisor está funcionando y detecta nuestros contenedores en el VPS.

Web de cAdvisor
Aunque podemos ver métricas (e incluso gráficas) de todos los contenedores no es muy “amistoso” y está bastante limitado. Pero su función principal es recolectar las métricas de los contenedores y eso lo hace perfectamente.
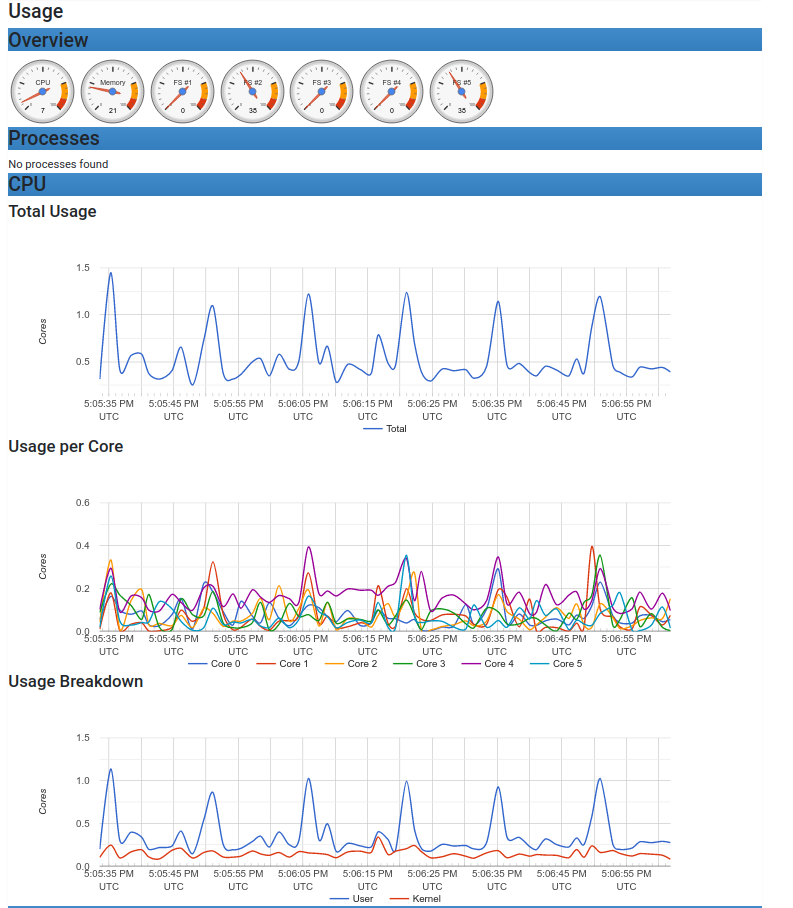
Gráficas en la web de cAdvisor
Prometheus
Ya tenemos cAdvisor funcionando. Vamos a configurar Prometheus creando su fichero de configuración:
|
|
Con el contenido:
|
|
En la sección global configuramos los períodos de polling a los origenes de métricas y el período de evaluación de reglas de alarmas.
Dejamos preparada la sección alerting donde configuraremos las reglas de alarmas. Y la sección rule_files.
En la seccion scrape_configs configuramos orígenes de métricas que queremos capturar. De momento configuramos el propio contenedor prometheus, que publicará sus metricas en el puerto 9090, y configuramos también el contenedor cadvisor que como ya vimos expone sus métricas en el puerto 8080. Al definir los orígenes de las métricas usamos los nombres de red de los contenedores (dentro de la red Docker) y asignamos a cada uno una etiqueta que nos permita distinguir los datos más tarde.
Ahora nos toca levantar el contenedor de Prometheus, modificamos el fichero docker-compose.yml:
|
|
Igual que con cAdvisor no queremos publicar el puerto de Prometheus en internet. En todo caso, si después nos interesa, lo expondremos via Traefik.
Igual que con cAdvisor podemos probar el acceso a Prometheus via túnel ssh. Una vez conectados al interfa web de Prometheus podemos comprobar el estado de los dos origenes de datos definidos para ver que los dos están activos (deberían).
Ejecutando:
|
|
Podremos acceder a nuestro nuevo Prometheus en http://localhost:9082. Si queremos hacer pruebas de consultas en la documentación oficial tenemos unos cuantos ejemplos.
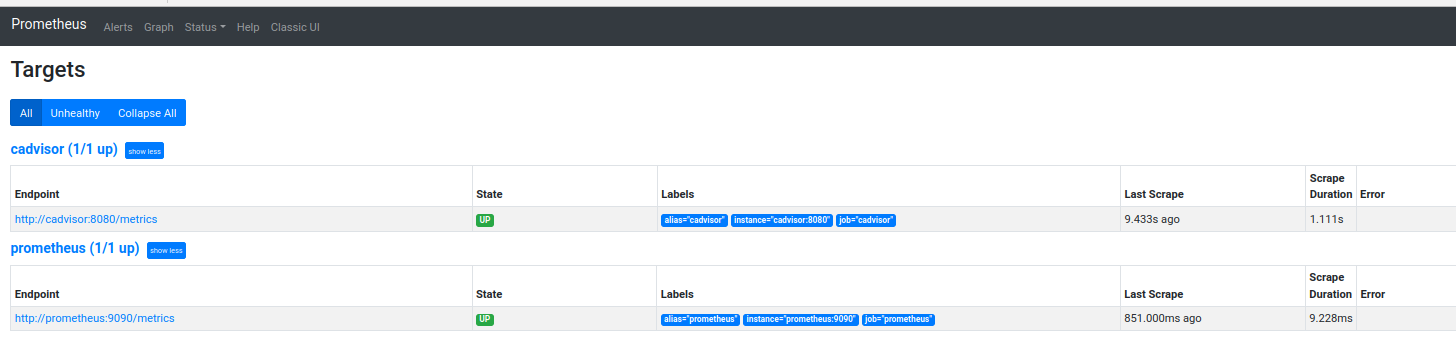
Orígenes de datos en la web de Prometheus
Grafana
Vamos a añadir Grafana a nuestra plataforma de monitorización. Grafana es un software especializado en la elaboración de cuadros de mando (_Dashboards) y representación gráfica de valores. Y lo hace francamente bien. Permite definir tanto los orígenes de datos como los propios Dashboards mediante ficheros de configuración o desde el interfaz web. Además los Dashboards pueden exportarse e importarse como ficheros .json. Incluso hay una página web donde se comparten los Dashboards entre usuarios.
La sección de Grafana en el fichero docker-compose.yml quedaría
|
|
Tenemos que preparar el fichero de entorno mon/grafana/grafana.env con los datos confidenciales de acceso a Grafana.
|
|
Con esta configuración ya podemos levantar el contenedor de Grafana y comprobar que podemos acceder sin problemas. (Claro que antes tenemos que declarar la ruta en la DNS Zone)
Web de Grafana
Como ya hemos comentado podríamos configurar completamente Grafana desde el interfaz web, pero vamos a crear la fuente de datos asociada a nuestro Prometheus desde el fichero de configuración de Grafana.
Para eso creamos el fichero mon/grafana/provisioning/datasources/datasource.yml con el contenido:
|
|
Una vez tengamos el fichero podemos reiniciar el contenedor de Grafana con dco restart grafana (docker-compose restart grafana si no usas mis alias). Después del reinicio podremos ver la nueva fuente de datos en la web de Grafana.
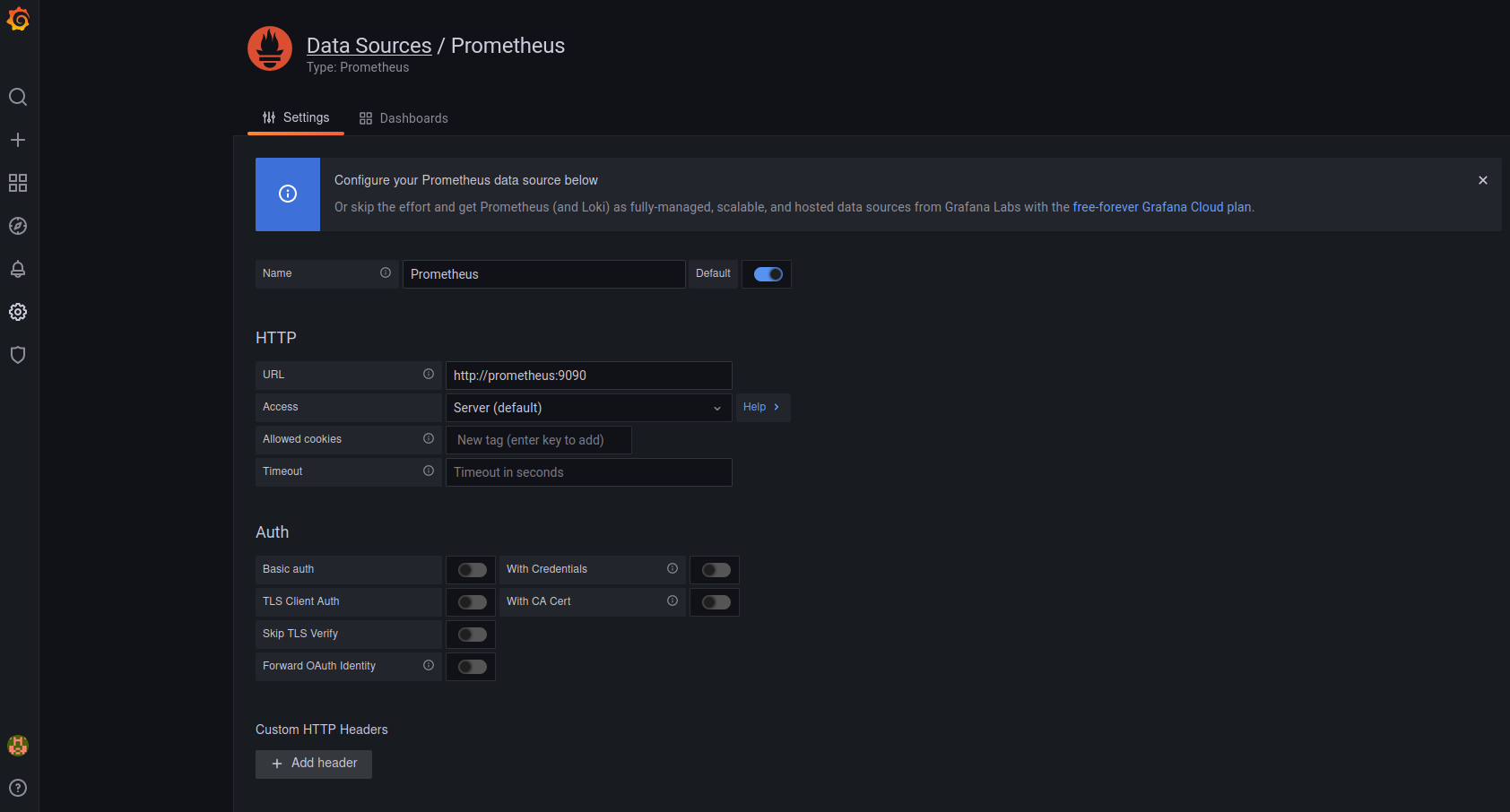
Grafana, datasource de Prometheus
Nuestro primer Dashboard lo importaremos directamente desde la web. Vamos a usar como ejemplo este Dashboard de la página web de Grafana. Vemos que tiene el id=193. Podríamos descargarlo como fichero .json pero nos basta con el id para probarlo. Clickamos en el signo + a la izquierda en la página web de nuestro Grafana y escogemos la opción Import. Basta con teclear el id 193 para que tengamos el Dashboard definido en Grafana.
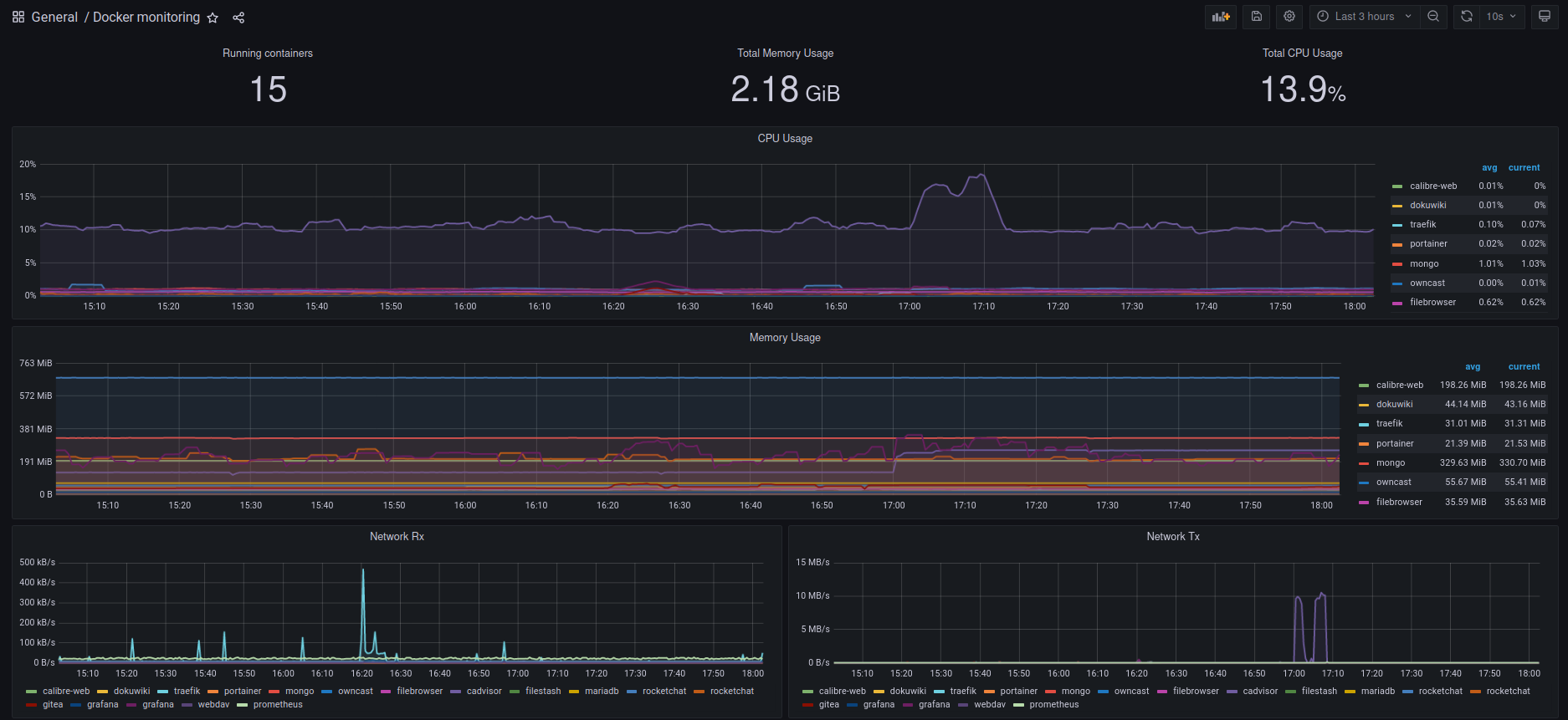
Grafana: Dashboard de Contenedores
Prometheus: Añadiendo Node Exporter
Si queremos que Prometheus capture también métricas de la maquina host, podemos instalar Node Exporter. La sección del fichero docker-compose.yml para el Node Exporter sería:
|
|
Tenemos que añadir el nuevo origen de datos en el fichero mon/prometheus/prometheus.yml (lineas 31 y siguientes) que nos quedaría:
|
|
Con la nueva fuente de datos definida podemos reiniciar el contenedor Prometheus con dco restart prometheus (docker-compose restart prometheus)
Podemos volver a conectarnos a Prometheus via túnel ssh como ya describimos y comprobar que los Targets son ahora tres y están todos arriba.
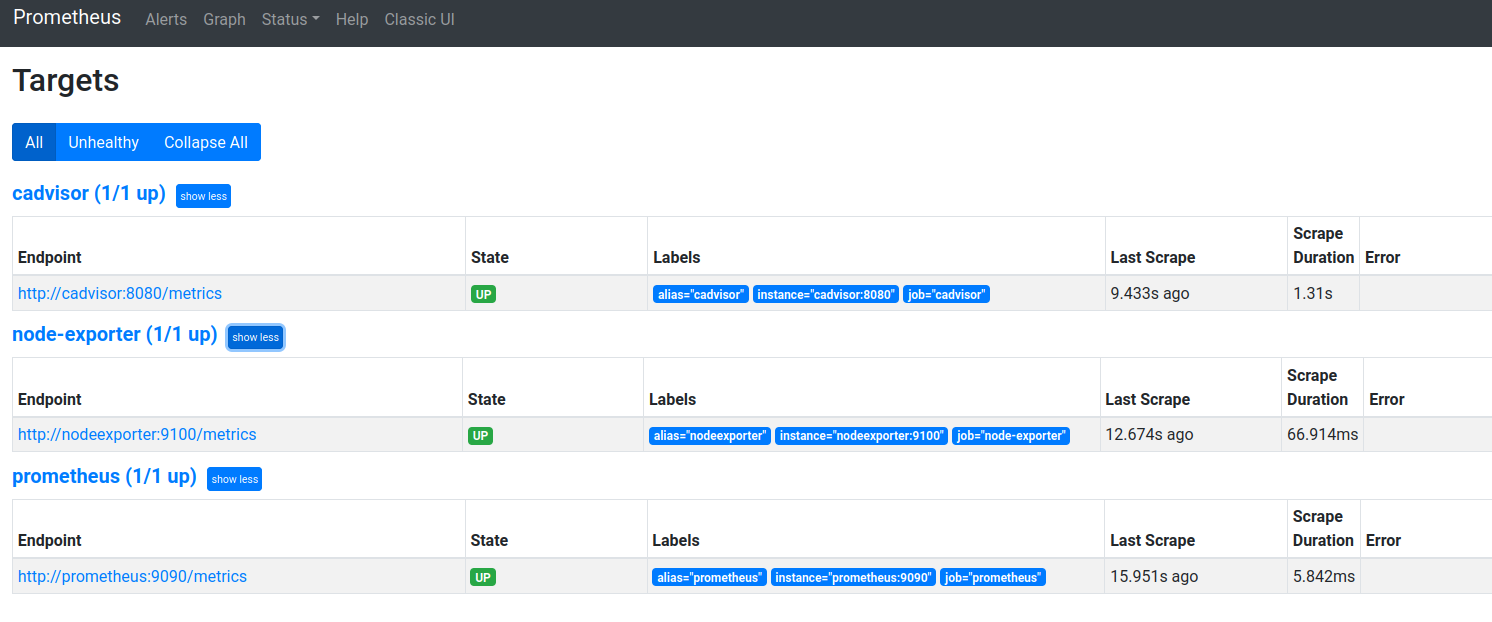
Prometheus con tres targets activos
Para ver los nuevos datos que aporta el Node Exporter a nuestro contenedor Prometheus tenemos que definir un nuevo Dashboard que nos los muestre en el contenedor Grafana.
Vamos a añadir el nuevo Dashboard definiendolo con un fichero .json para ello definiremos dos ficheros en nuestro directorio mon/grafana/provisioning/dashboards (más info)
El primer fichero dashboard.yml define el provider y tiene el siguiente contenido:
|
|
En el segundo fichero dco_prom.json definiremos el Dashboard que hemos copiado de aquí.
Si reiniciamos ahora el contenedor de Grafana, dco restart grafana veremos que ya tenemos los dos Dashboard disponibles; el que añadimos desde la red y el que hemos añadido ahora mismo por fichero.
En el nuevo Dashboard podemos ver ya métricas del host, como la memoria usada, la carga de CPU del host y la capacidad del sistema de ficheros.
Vemos también que el nuevo Dashboard viene preparado para visualizar Alerts pero no tenemos ninguna definida (todavía).
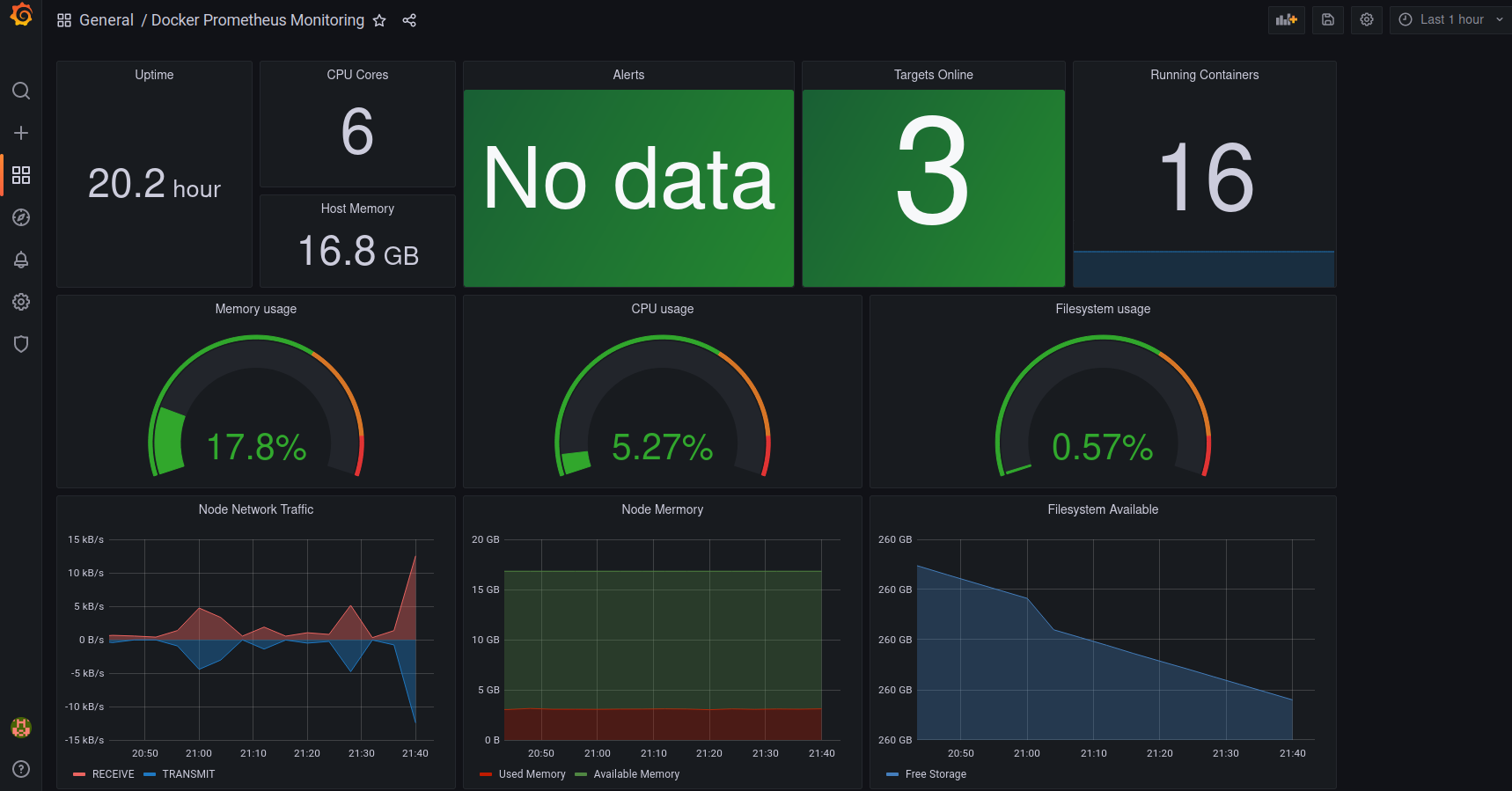
Dashboard con datos de Node Exporter
Prometheus: Definición de Alarmas
Vamos a definir condiciones de Alarma en Prometheus. Necesitamos crear un nuevo fichero mon/prometheus/alert.rules, donde definiremos un par de alarmas:
|
|
Tenemos que editar también el fichero mon/prometheus/prometheus.yml para añadir nuestro fichero alert.rules en la sección de rule_files que quedaría así:
|
|
Si rearrancamos Prometheus (ya sabes dco restart prometheus o docker-compose restart prometheus) y se cumplen las condiciones para la alarma podremos verla en el Dashboard:
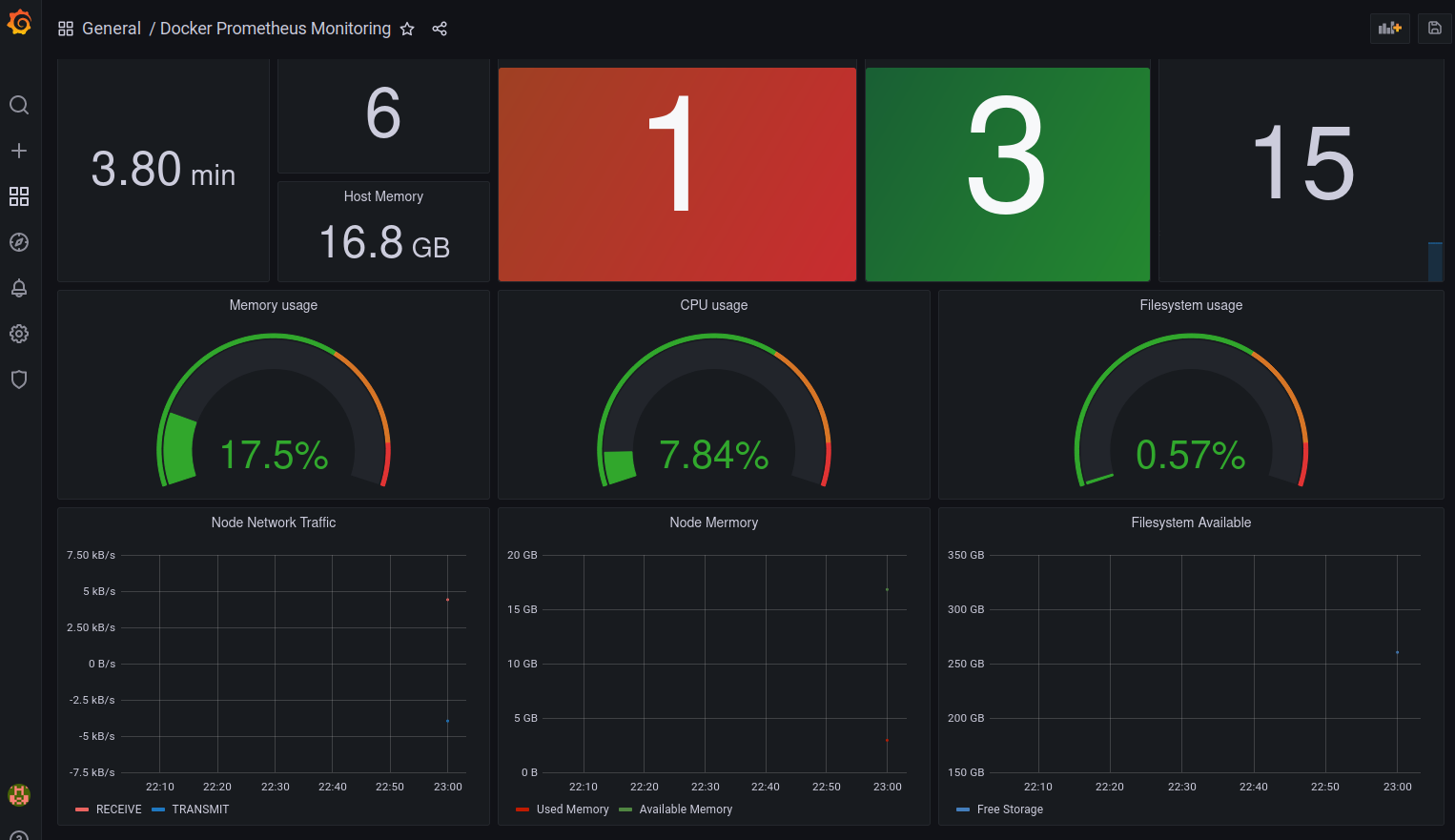
Dashboard con Alarma
Las alarmas que hemos definido no tienen demasiado sentido, pero antes de profundizar en como definir alarmas significativas vamos a configurar las notificaciones a través de Alert Manager.